Abstract
Due to the rapid generation and dissemination of information, large language models (LLMs) quickly run out of date despite enormous development costs. Due to this crucial need to keep models updated, online learning has emerged as a critical necessity when utilizing LLMs for real-world applications. However, given the ever-expanding corpus of unseen documents and the large parameter space of modern LLMs, efficient adaptation is essential. To address these challenges, we propose Memory of Amortized Contexts (MAC), an efficient and effective online adaptation framework for LLMs with strong knowledge retention. We propose an amortized feature extraction and memory-augmentation approach to compress and extract information from new documents into compact modulations stored in a memory bank. When answering questions, our model attends to and extracts relevant knowledge from this memory bank. To learn informative modulations in an efficient manner, we utilize amortization-based meta-learning, which substitutes the optimization process with a single forward pass of the encoder. Subsequently, we learn to choose from and aggregate selected documents into a single modulation by conditioning on the question, allowing us to adapt a frozen language model during test time without requiring further gradient updates. Our experiment demonstrates the superiority of MAC in multiple aspects, including online adaptation performance, time, and memory efficiency.
Method
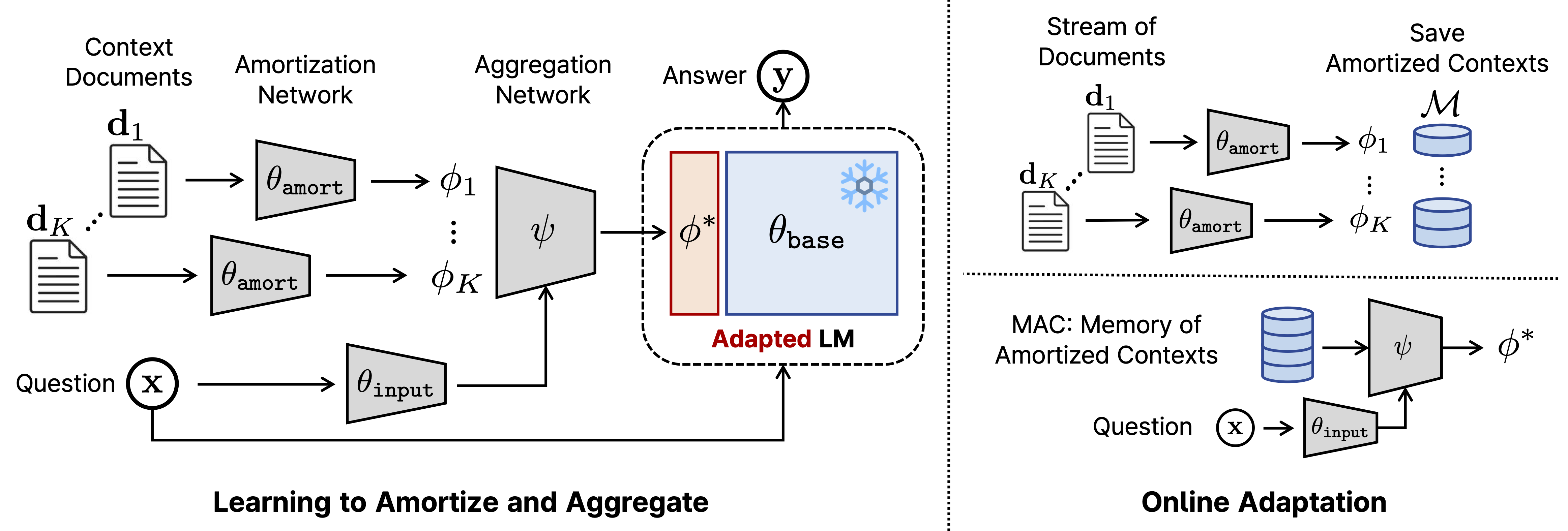
We propose Memory of Amortized Contexts (MAC), an efficient and effective online learning framework for static LMs. The core idea of MAC is to freeze the parameter of the LM and instead edit the LM by using a predicted Parameter Efficient FineTuning (PEFT) modulation, which capturing relevant knowledge from hitherto unseen documents. Specifically, we utilize amortization-based meta-learning to compress a new document's information into a compact modulation where such modulation maximizes the task performance of the adapted LM (e.g., question-and-answer ability). Then, we learn to aggregate documents represented in feature space into a single modulation based on a given question. During the online adaptation stage (or test-time), we thus store each instance of a document stream in a memory bank, which we attend over to extract relevant information when a new query is given.
Experimental Results
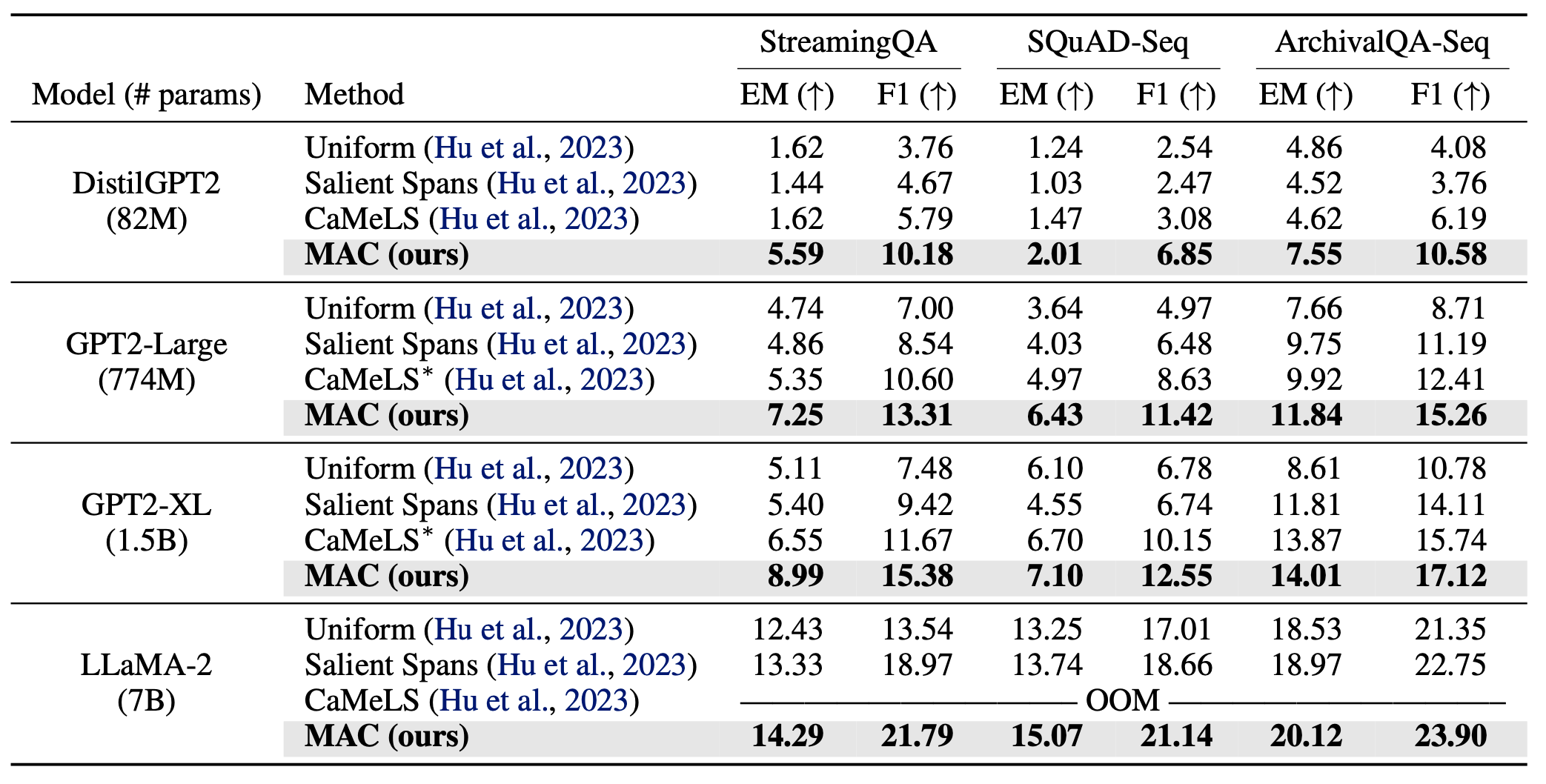
Online adaptation performance: We report the exact match (EM) and F1 score by adapting the LM on a stream of documents and then performing QA based on the learned data. Overall, MAC significantly outperforms all the prior online finetuning methods.
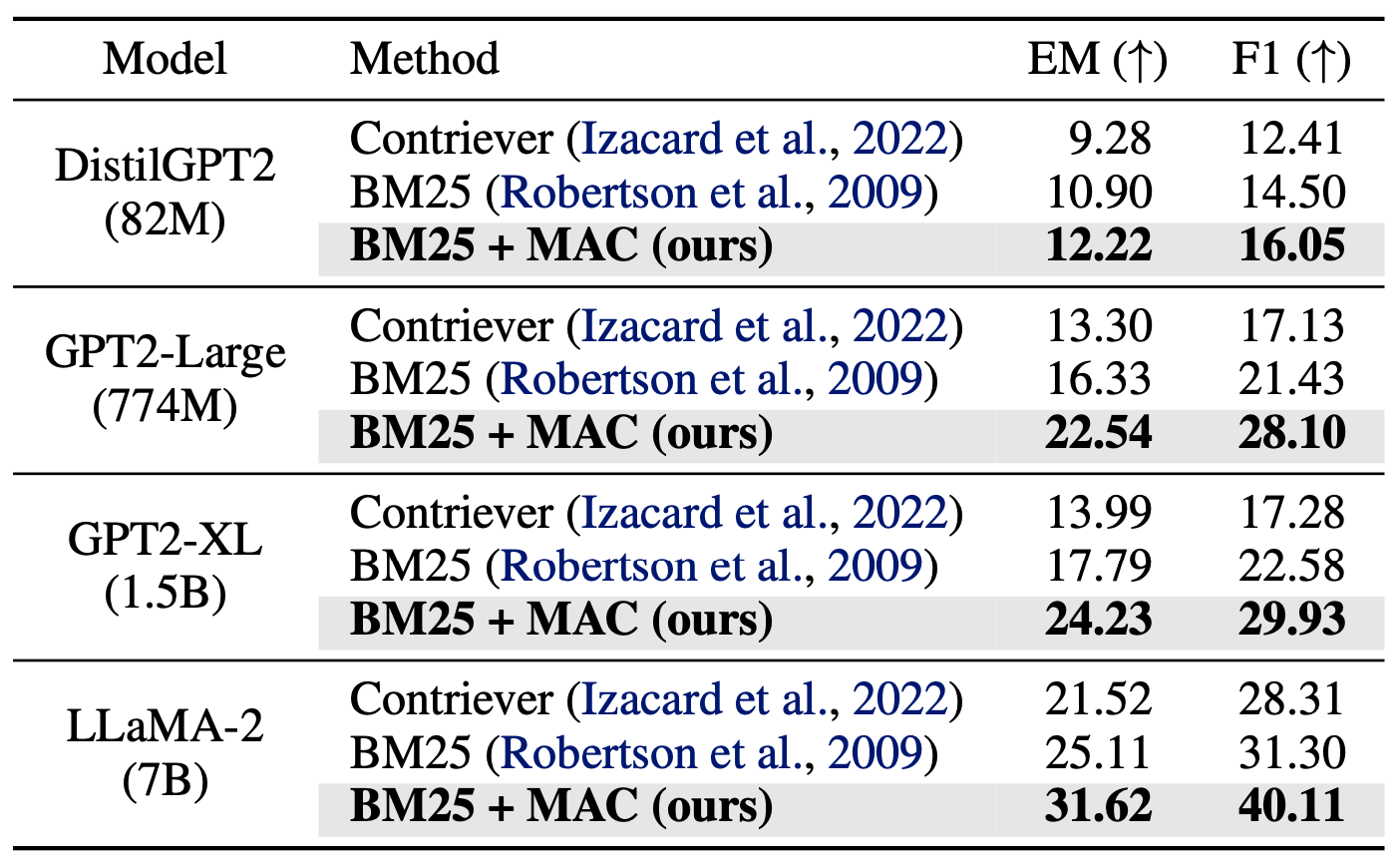
Improving MAC with retrieval augmentation: We show that MAC can be further improved by using retrieval augmentations. As shown in the table above, using BM25 with MAC significantly improves the performance by a large margin in all cases. More interestingly, the improvment seems to increase with model size.
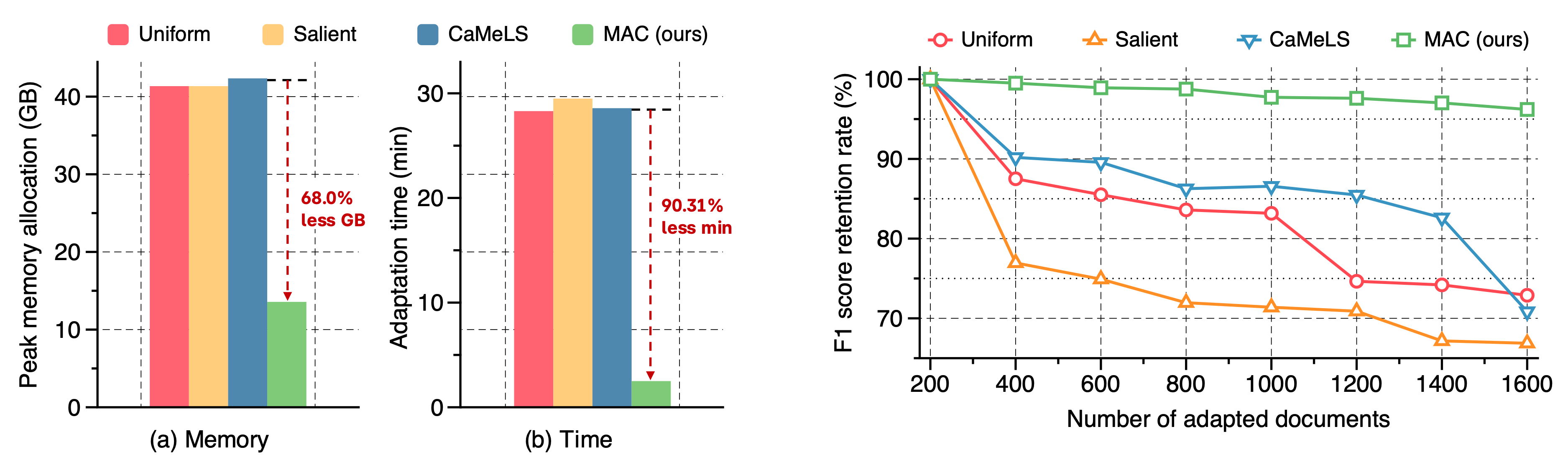
Adaptation efficiency of MAC (left): MAC is significantly efficient in both memory and adaptation time compared to other online finetuning methods; we note that MAC does not require any gradient computation to update the model, while online finetuning needs the gradient to update the model.
Knowledge retention of MAC (right): MAC shows a strong knowledge retention compared to other online finetuning methods. This result indeed highlight i) the benefit of using a memory bank as a tool for preserving knowledge and ii) our aggregation mechanism well predicts the modulation even when the memory bank's cardinality increases throughout the adaptation process.
MAC Explained
Citation
|
@article{tack2024online,
title={Online Adaptation of Language Models with a Memory of Amortized Contexts}, author={Tack, Jihoon and Kim, Jaehyung and Mitchell, Eric and Shin, Jinwoo and Teh, Yee Whye and Schwarz, Jonathan Richard}, journal={arXiv preprint arXiv:2403.04317}, year={2024}, } |